«Дальнее чтение» «Горького»
Какие можно сделать выводы? Довольно много упоминаний Сталина и Гитлера, есть и другие современные политики, но гораздо более важная фигура — Л. Толстой (важен для И. Перникова, Л. Оборина, С. Нарановича, К. Мильчина, Б. Куприянова, И. Козлова). Г. Юзефович важна для Л. Оборина и В. Владимирского. Пушкин — для М. Нестеренко, И. Напреенко, И. Мартова. Достоевский — для И. Перникова, М. Нестеренко, Б. Куприянова. Как видно по облакам слов, среди топовых выделяются авторы с бэкграундом, отличным от филологического (и/или пишущие на другие темы): Н. Проценко, С. Наранович, И. Напреенко, Д. Борисов. В целом топовых авторов отличает литературная и социальная критика левой ориентации.
Тематическое моделирование
Авторы «Горького» пишут о самых разных книгах: не только художественных, но и научных, о книгах на разных языках и разных столетий. В «Горьком» есть интервью с различными учеными, писателями, издателями и публичными людьми. Более того, за пределами топ-15 специализация авторов «Горького» гораздо шире. Интересно узнать, на какие тематические коллекции можно разделить тексты «Горького», не читая более 4000 текстов. Прагматика этого для электронного издания в том, что каждый текст получит тематический хештег, которым сможет воспользоваться читатель, если захочет просмотреть публикации, похожие на тот текст, который он только что прочел. Одно из решений — выдавать тексты того же автора или с теми же ключевыми словами. (Этот способ не всегда работает: один и тот же автор может писать на совершенно разные темы; об одном и том же можно говорить совершенно разными словами или из перспективы разных дисциплин.) Лучше показывать тексты похожей тематики или похожие по содержанию.
Важно также отметить, что текст редко посвящен только одной-единственной теме: как правило, любой материал — микс из нескольких сквозных тем, присутствующих в нем в разных пропорциях. Таким образом, у одного текста может и должно быть несколько тегов или тематик.
Для этого и нужно тематическое моделирование корпуса текстов. Есть три наиболее распространенные статистические модели, или формулы, используемые для этого: латентно-семантический анализ (LSA), вероятностный LSA (PLSA), латентное распределение Дирихле (LDA). Не буду подробно вдаваться в матчасть, о ней есть отличные лекции К. Воронцова. Для тематического моделирования «Горького» я воспользовался LDA-моделью, которая, как и остальные, реализована в библиотеке Genism для python. Использование этой модели также требует предобработки текстов. Внутри LDA — мешок слов. Тексты передаются в виде списка лемм, соответствующих текстов, обрабатываются не целиком, а по частям, чтобы хватило вычислительных мощностей. Обработка тоже идет итеративно: модель несколько раз повторяет расчеты, чтобы повысить точность.
Загвоздка в том, что в модель необходимо передать количество тем, которые будут выделены в корпусе текстов в зависимости от специфических для этих тем ключевых слов. Качество модели измеряется средней когерентностью выделяемых тем. У каждой из тем своя когерентность, которая определяется долей ключевых слов этой темы в текстах, отнесенных к ней по сравнению с долями ключевых слов из других тем. (Есть две метрики когерентности: u_mass и с_v.) Оптимальное количество тем можно подобрать, последовательно обучая LDA-модели со все большим количеством тем и следя за динамикой средней когерентности. После определенного количества тем их средняя когерентность, как правило, перестает расти. Чем разнообразнее корпус текстов, тем на большее количество тем его следует делить.
Однако, помимо математической метрики, есть еще человеческая интерпретируемость выделенных моделью тем. Иными словами, может ли человек, взглянув на выделенные моделью ключевые слова для каждой из тем, с легкостью понять, что это за тема, т. е. назвать ее, озаглавить. Проблема интерпретируемости усугубляется тем, что множества ключевых слов, относящихся к разным тематикам, могут частично пересекаться. Поэтому к человеческой интерпретируемости ближе мера сходства Жаккара. Подбор оптимальной темы должен максимизировать когерентность тем и минимизировать сходство между ними.
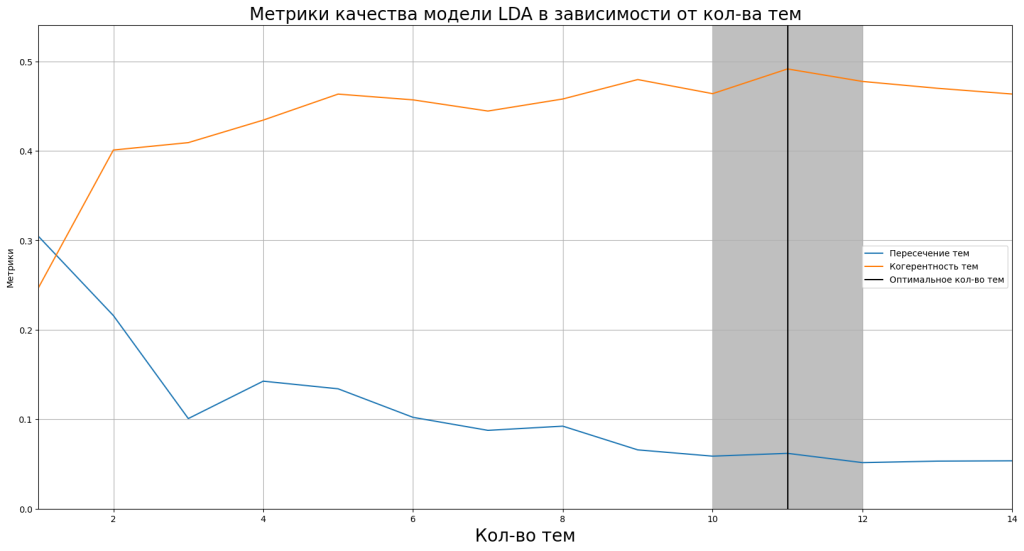 Оптимальное количество тем для LDA-модели Горького — 11.
Оптимальное количество тем для LDA-модели Горького — 11.
Для каждой из 11 выделенных тематик я построю график по 10 ключевым словам, который показывает, как часто ключевое слово встречается в текстах, отнесенных к теме, и какова его важность для выделения темы.
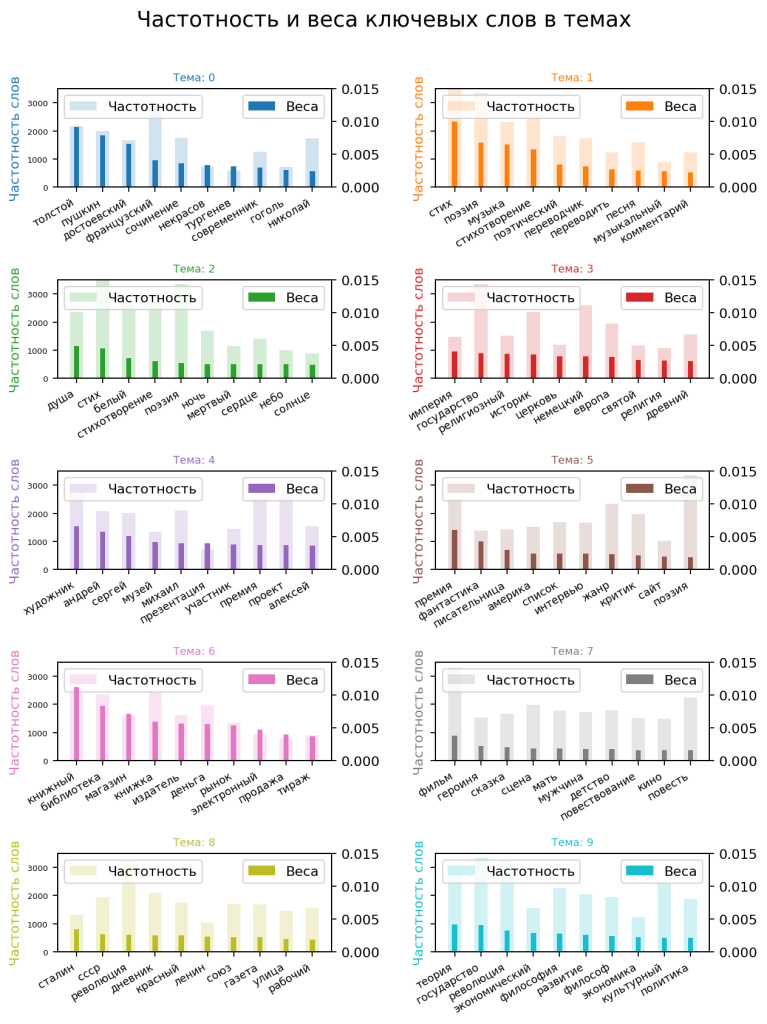
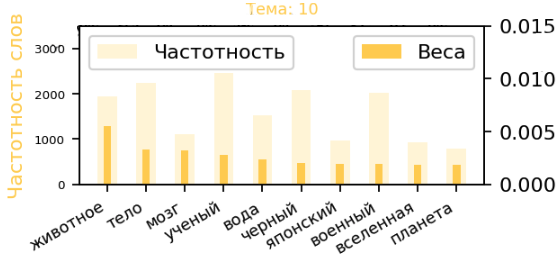 Озаглавим темы по их ключевым словам (на графиках выше их по 10, можно выводить и больше):
Озаглавим темы по их ключевым словам (на графиках выше их по 10, можно выводить и больше):
Тема_0: Русская классика, отечественная проза
Тема_1: Лирика, критика, переводная литература, музыка
Тема_2: Душа, поэзия, телесность, философия
Тема_3: Сравнительная история (история государства, религии; военная история)
Тема_4: Культурные проекты, мероприятия, литературные премии
Тема_5: Фантастика, премии
Тема_6: Издательское дело, рынок
Тема_7: Литература и драматургия, феминизм
Тема_8: Революция 1917 года, СССР, память
Тема_9: Социальные науки (социология, политология, экономика, философия)
Тема_10: Естественные науки (биология, физика, астрономия), Япония
Как можно заметить, Тема_1 и Тема_2 пересекаются в «поэзии» («стих» и «стихотворение» — контекстуальные синонимы), Тема_3 и Тема_9 пересекаются в «государстве», Тема_8 и Тема_9 — в «революции», Тема_4 и Тема_5 — в «премии». Тему_1: Лирика, критика, переводная литература, музыка и Тему_2: Душа, поэзия, телесность, философия как будто бы можно объединить в одну. Вероятно, их можно объединить и с Темой_7: Литература и драматургия, феминизм. Возможно, из-за большого количества текстов, написанных отдельными авторами из топ-15 по в целом одной (или похожей по смыслу) тематике, модель фиксирует уникальный для них язык в качестве разных тематик. (Так, Тема_1 — это в большинстве своем тексты Л. Оборина.) В данном случае хорошим показателем качества модели является то, насколько успешно она объединяет различных авторов, пишущих на одну тематику, а также разделяет тексты одного автора разной тематики, вопреки языковому и стилистическому сходству.
В итоге LDA-модель представляет каждый текст в виде микса тем в определенных пропорциях в зависимости от представленности в нем ключевых слов, характерных для той или иной темы. Например, текст Б. Колоницкого «Кто первый идет за гробом, тот и главный» от 14.12.22 с подзаголовком «О политике памяти и новинках издательства ЕУСПб» LDA представляет так:
(номер темы, ее доля)
[(0, 0)
(1, 0.039592195)
(2, 0)
(3, 0.5091702)
(4, 0)
(5, 0)
(6, 0)
(7, 0)
(8, 0.15597652)
(9, 0.29443944)
(10, 0)]
Это означает, что, согласно модели, это на 50% Тема_3: Сравнительная история (история религии, государства; военная история) и на 30% Тема_9: Социальные науки (социология, политология, экономика, философия), на 2% Тема_8: Революция 1917 года, СССР, память. В принципе, это неплохой и достаточно осмысленный результат. Б. Колоницкий — один из ведущих отечественных культурных историков революции 1917 г. и межвоенного времени. Культурная история предполагает реконструкцию того, как (при помощи каких слов) современники исторических событий понимали и конструировали значение происходящего и объяснение того, почему они делали это так, т. е. антропологическая, философско-герменевтическая, культурологическая и социологическая составляющие культурной истории действительно огромны. Текст представляет собой транскрипцию презентации новых книг Европейского университета из серии «Эпоха войн и революций», общая тема которых — изучение опыта современников Первой мировой и Гражданской войн в России. То есть доля Темы_8: Революция 1917 года, СССР, память могла бы быть заметно выше. Однако в тексте также есть ответы Б. Колоницкого на вопросы слушателей о методологии memory studies, к тому же по сравнению с другими текстами «Горького», отнесенными моделью к Теме_8, Б. Колоницкий использует другой язык, или доля ключевых для Темы_8 слов невелика (книга все-таки о Гражданской войне, а не о революции 1917 года, которую, как следует из текста, белые предпочитали называть «красной смутой»).
Найдем 20 текстов, которые по миксу тем (согласно LDA-модели) больше всего напоминают текст Б. Колоницкого выше. Для этого умножим матрицу, где строки — тексты корпуса «Горького», а столбцы — доли тем в тексте на вектор текста Б. Колоницкого, т. е. только соответствующие ему веса тем, затем отсортируем результат и возьмем индексы текстов, для которых он минимален, т. е. микс тем тот же, что у текста Б. Колоницкого или близкий к нему. Близкими модель считает следующие тексты:
А. Ранчин (27.06.2022): об одной из основополагающих русских летописей
Ф. Никитин (16.05.2023): семь книг о баптизме в России
А. Ранчин (09.03.2022): о самом раннем из дошедших до нас произведений древнерусской литературы
Н. Родосский (19.01.2022): о книге Яна Ассмана «Политическая теология между Египтом и Израилем»
Д. Стахов (03.10.2018): обзор новых книг по отечественной истории
А. Ранчин (23.08.2022): о первом древнерусском житии князя‑воина
Н. Проценко (23.05.2019): рецензия на книгу о формировании украинской нации
Н. Проценко (23.05.2021): о книге «Империи Средневековья: От Каролингов до Чингизидов»
Д. Стахов (22.02.2017): о Московском государстве накануне конца света и «ереси жидовствующих»
Ф. Никитин (25.12.2023): семь книг о меннонитах и их вере
А. Ранчин (11.08.2022): о житии двух святых, казненных по политическим мотивам
К. Галеев (11.06.2019): рецензия на книгу Майкла Ходарковского «Степные рубежи России»
И. Перников (23.08.2023): о книге Андрея Банникова «Быть легионером»
А. Ранчин (05.10.2022): о житии игумена земли Русской
И. Юрченко (23.09.2020): о книге Амирана Урушадзе «Вольная вода»
Д. Стахов (27.06.2017): от Золотой Орды до религиозного раскола
Как можно понять по миксу тематик, в похожих 20 текстах подобрались такие материалы, в которых, как и у Б. Колоницкого, ок. 50% Сравнительная история (история религии, государства; военная история) и ок. 30% Социальные науки (социология, политология, экономика, философия), а также есть примесь отечественной истории. В итоге, как очевидно из подзаголовков, среди них много текстов о книгах по истории религии на Руси и сравнительной истории, о межвоенном периоде — пара книг, только один текст о книге о Гражданской войне. Семантики немного не хватает, хотя дисциплинарный подбор верен. Рецензия И. Перникова на книгу А. Банникова «Быть легионером» может помочь что-то понять не только о легионерах Римской империи, но и о солдатах империй, сражавшихся в Первой мировой.
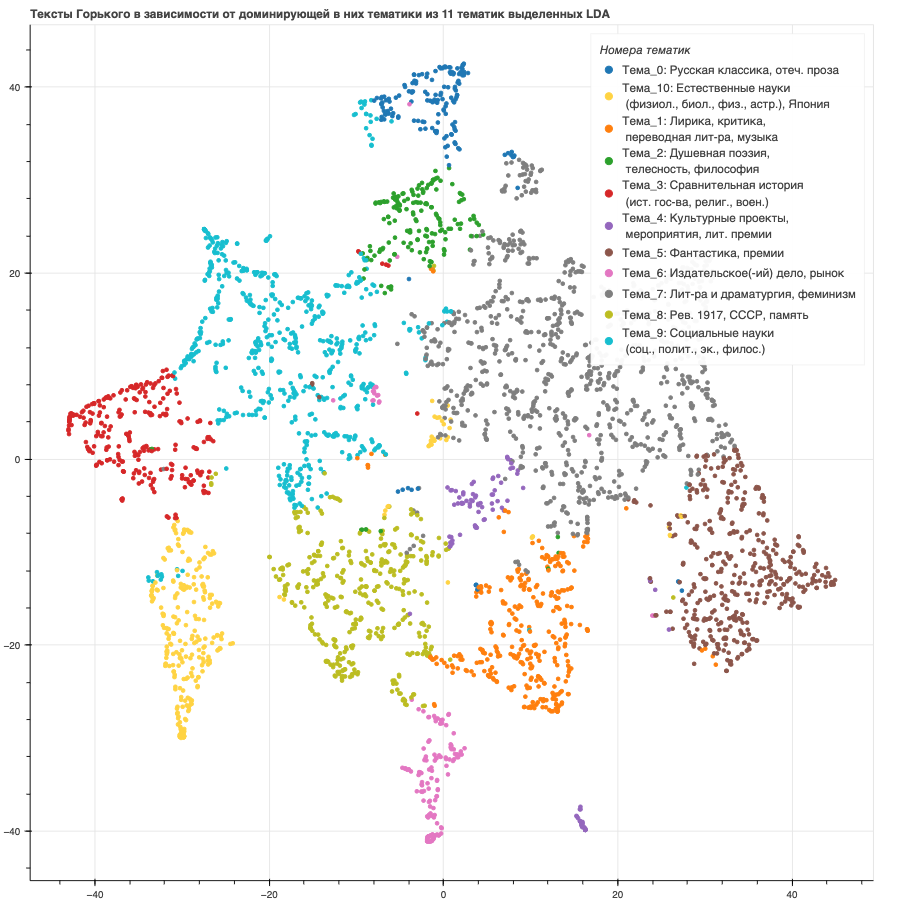
Модель LDA также дает возможность представить весь корпус текстов «Горького» в виде точек на двумерной плоскости (диаграмма рассеяния), где цвет точек — доминирующая тематика текста. График ниже, но не будем останавливаться на нем.
 Эмбеддинги трансформеров и латентно-семантический анализ
Эмбеддинги трансформеров и латентно-семантический анализ
Проблема латентно-семантического анализа на основе векторного представления слов с помощью их TF-ID метрики в том, что подобные частотные модели (на основе встречаемости слов в отдельном документе и в корпусе в целом) не учитывают порядок слов и контекст, а значит, для них «скрипичный ключ» и «гаечный ключ» — это один и тот же «ключ». К счастью, эта проблема решается с помощью дистрибутивной семантики, или графового представления слов. В таком случае смысл слова определяется именно контекстом, в котором оно употребляется.
Не станем углубляться в математику, просто представьте, что нейросеть видела много текстов и «запомнила», в каких контекстах обычно употребляются те или иные слова. Эту информацию о контексте слова, представленную в виде одномерного вектора, она и принимает за его семантику. Например, эмбеддинги/векторы слов «кошка» и «собака» похожи, поскольку употребляются в одном контексте (условно, контекст «домашние животные / питомцы»), эмбеддинг «кошки» будет ближе к эмбеддингу «собаки», чем к эмбеддингу «короля», а, в свою очередь, эмбеддинг «короля» ближе к эмбеддингу «государства» (условно, контекст «политика/правление» — см., например, тут).
Для получения эмбеддингов не только слов, но и целых текстов используют нейросетевые модели, известные как трансформеры, которые при кодировании учитывают порядок слов в кодируемом тексте. (Бывают трансформеры-энкодеры, т. е. кодировщики и декодеры, а также трансформеры, объединяющие и то и другое, — к последним как раз относятся модели типа GPT, которые на вход принимают осмысленный текст и на выходе дают осмысленный текст.) Для получения эмбеддингов, как правило, достаточно предобученных энкодерных трансформеров типа BERT. Проблема в том, что контекст трансформеров (т. е. количество слов, принимаемых на вход до «забывания» нейросетью того, что было в начале) ограничен.
Получение эмбеддингов — это времязатратный процесс, требующий вычислительных мощностей. Как правило, трансформерами пользуются на видеокартах. К счастью, Google Colab позволяет использовать определенное количество видеокарт Т4 в день. К тому же эмбеддинги всех спаренных текстов «Горького» можно получать частями. Так или иначе, проблема ограниченного контекста трансформерных моделей всегда будет актуальна в силу самой их нейросетевой архитектуры; чтобы сделать большими и внимание, и память, языковая модель должна разрастись до огромных размеров (в терминах количества параметров), как раз таких, как современные модели типа GPT, обучение которых требует огромного количества информации.
Перед получением эмбеддингов каждый текст разделялся на фрагменты по 1000 пробельных слов с пересечением разделяемых фрагментов. Затем эти фрагменты передавались в модель. Я попробовал эмбеддинги двух моделей SBERT (Sentence-BERT, т. е. BERT для предложений) и YandexGPT Light. Последние предсказуемо показали себя лучше. Чем больше трансформерная модель (больше текстов видела и больше параметров имеет), тем лучше эмбеддинги (в том числе длиннее дробная часть чисел в них). Получить эмбеддинги YandexGPT можно, если обратиться к модели через API c помощью библиотеки Langchain для python, которая, помимо прочего, призвана решить проблему длины контекста.
Еще одним узким моментом, как выяснилось постфактум, оказалась длина текстов, подаваемых в модель для получения эмбеддингов. Как видно из гистограмм в начале, в «Горьком» встречаются тексты разной длины — самые длинные в три или четыре раза длиннее самых коротких. Технически дополнить эмбеддинги коротких текстов нулями до длины самых длинных (такая процедуры называется «паддиг») не составляет проблемы. Однако выяснилось, что при кластеризации эмбеддинги коротких текстов всегда объединяются в одну группу (см. ниже), несмотря на различие смыслов этих текстов. (Так нули из незначимых стали очень важными.) Сжатие векторов до размеров меньшей длины (в пробельных словах) самого маленького текста означало бы потерю заметной части смысла длинных текстов. В итоге я оставил короткие тексты без изменения, а длинные обрезал до получения эмбеддингов по длине ок. 4000 пробельных слов (токенов). В итоге эмбеддинги получились длиной 1024.
Отмечу, что по невыясненной причине (неизвестная ошибка) YandexGPT отказался выдавать эмбеддинги следующих девяти текстов (приведу в формате Ф. И. автора и дата публикации в «Горьком»): Чубаров И. 2021-07-19; Incognito 2020-10-13; Гранд А. 2020-08-16; Incognito 2018-07-18; Мартов И. 2017-09-25; Incognito 2016-11-30; Гранд А. 2023-04-26; Лукоянов Э. 2019-02-27; Пищикова Е. 2018-07-18. Ничего общего между этими текстами, отличающего их от остальных, я не нашел. У YandexGPT есть табуированные темы, на которые он отказывается говорить, но запретных тем для получения эмбеддингов, насколько мне известно, нет. Возможно, имели место ошибки при парсинге, которые не получается установить автоматически (проверки форматов и чистка нечитаемых символов) или выявить визуально. Мои извинения авторам. Так или иначе, это капля в море оставшихся 4243 текстов.
После получения эмбеддингов я кластеризовал их, чтобы объединить тексты по смыслам. В отличие от модели LDA, которая группировала по распределениям ключевых слов, в данном случае мы группируем по смыслам текстов, представленным в виде численных векторов, с которыми можно производить математические операции.
Существует множество разновидностей кластерного анализа: кластерный анализ методом к-средних (k-means), иерархическая кластеризация (агломеративная или дивизивная), кластеризация на основе плотности распределения (DBSCAN) и т. д. Разные методы применимы, лучше себя показывают для разных распределений точек и дают различающиеся результаты. Я использовал k-means и агломеративную кластеризацию (с косинусным расстоянием).
Модель k-means, как и LDA, требует указать, на какое количество кластеров необходимо разделить тексты. Оптимальное количество кластеров необходимо подбирать итеративно, обучая модели с увеличивающимся количеством кластеров и ориентируясь на метрики качества. (Для k-means есть три метода, метрики получения оптимального количества кластеров: метод локтя (минимизация инерции), метод силуэта (максимизация метрики silhouette_score) и метод на основе гэп-статистики.) Часто эти метрики свидетельствуют в пользу различного количества кластеров в качестве оптимального. Так вышло и в этот раз.