Все мы начиная с 24 февраля 2022 года оказались перед лицом наступающего варварства, насилия и лжи. В этой ситуации чрезвычайно важно сохранить хотя бы остатки культуры и поддержать ценности гуманизма — в том числе ради будущего России. Поэтому редакция «Горького» продолжит говорить о книгах, напоминая нашим читателям, что в мире остается место мысли и вымыслу.
— Вы закончили исторический факультет МГУ, а затем защитили кандидатскую в Высшей школе экономики по теме «Представление о святости в официальной католической мысли второй половины XIII века». Сейчас один из ваших центральных интересов — это Digital Humanities. Как у вас зародился интерес к компьютерной гуманитаристике?
— Получилось это довольно случайным образом. Я работала в ВШЭ после защиты, и меня отправили в качестве приглашенного преподавателя по обмену в Национальную школу хартий. Это одна из старейших парижских школ, где обучают палеографов; ей недавно исполнилось двести лет. Я должна была вести семинары, которые сопровождали курс лекций по истории права и которые не имели никакого отношения к Digital Humanities. Однако они были отменены из-за болезни профессора, и я оказалась в Париже с визой и зарплатой, но абсолютно без дела. Поэтому единственное, что мне оставалось, — это пойти на какие-нибудь курсы в том университете, где я находилась.
В Школе хартий магистратура по Digital Humanities состоит из двух сегментов: первый для исследователей, а второй для тех, кто сохраняет историко-культурное наследие, то есть для архивистов, музейщиков и так далее. Я слушала курсы в первом, и в моей личной истории отношений с медиевистикой это стало ренессансом, потому что мне, честно говоря, осточертели те сюжеты, которыми я занималась во время защиты и после нее, а новые инструменты дали новое дыхание. У меня всегда было ощущение, что я плохо понимаю методологию своих собственных исследований, и мои чисто исторические исследования казались мне реферативными. Получив же в распоряжение цифровые инструменты, я стала понимать, какое исследование я провожу и какой результат получаю. Это для меня значительно более наглядно и понятно.
 Светлана Яцык. Фото: Vox medii aevi
Светлана Яцык. Фото: Vox medii aevi
— Какой темой в медиевистике вы занимались раньше и что сейчас находится в вашем исследовательском поле зрения?
— Я раньше занималась двумя большими сферами. Во-первых, я занималась историей святости с точки зрения церковного и канонического права, то есть тем, как канонизировали святых. Во-вторых, я занималась францисканской интеллектуальной историей на примере сочинений конкретного персонажа — Иоанна Уэльского, выходца из Уэльса, который большую часть жизни провел и проработал в Париже.
В первом случае я работала с протоколами канонизационных процессов. Это довольно однотипные, формульные источники, которые не так интересно читать, как какие-нибудь хроники. А в случае с Иоанном я работала с его трактатами. В них меня особенно сильно занимало, с одной стороны, то, как он представлял себе знание, и то, какие формы знания он выделял: богодухновенные и небогодухновенные, мудрость, философию и так далее. А с другой стороны, учитывая, что у Иоанна есть такая особенность — он очень интенсивно апеллирует к примерам из жизни язычников в своих сочинениях, — мне было любопытно, как он составлял учебники для проповедников, в которых приводил примеры, то есть exempla. Это такие назидательные истории, анекдоты, которые вставляются в проповедь, и все на этом примере понимают, как надо или не надо себя вести. Его exempla очень часто содержат эпизоды из жизни античных философов или античных героев — например, он пишет про Одиссея. До этого такими вещами занимался Иоанн Солсберийский, а после — уже всякие гуманисты или так называемая классицизирующая нищенствующая братия из Англии. Короче, это нетипично для XIII века, и я пыталась понять, как же так вышло.
Но проблема в том, что для того, чтобы ответить на оба этих вопроса, нужна просто титаническая эрудиция, которой, как мне кажется, я не обладаю, потому что я медленно читаю на латыни. Всегда найдется какой-нибудь ирландец, который, оказывается, тоже писал про античных философов в XIII веке, и мне казалось, что едва ли я стану когда-нибудь достаточно «экспертной», чтобы с уверенностью делать какие-то содержательные выводы относительно того, уникален Иоанн Уэльский в чем-нибудь или нет. Из этой ситуации может быть, как мне показалось, два выхода: с одной стороны, критические издания и внимание к материальности текста и к рукописи как к объекту; а с другой стороны — дальнее чтение, исследование больших объемов текста, которые не может «переварить» один человек или мои старшие коллеги, которые не применяют цифровых методов, а мы с компьютером можем.
Один из трактатов Иоанна Уэльского, Breviloquium de virtutibus, сложно идентифицировать с точки зрения жанра: это и энциклопедия, и сборник exempla, и зерцало принцев — словом, такой назидательный учебник для будущей правящей элиты, и в целом было непонятно, как автор сам его мыслил. Мне хотелось посмотреть, как его текст воспринимали те, кто его копировал. Поэтому я составила базу данных с описанием рукописей, в которых циркулировал Breviloquium, и посмотрела на то, тексты каких жанров соседствовали с этим сочинением, чтобы понять, как менялось восприятие жанра этого текста в динамике. Это было исследование, которое, безусловно, еще никем до меня не проводилось и результат которого виден сразу.
А сейчас я работаю в проекте Distinguo, которой посвящен сборникам так называемых дистинкций, distinctiones. Это такие коллекции слов, которые могут пригодиться проповедникам; как правило, сборники выстроены по алфавиту и каждый термин сопровождает его историческое, аллегорическое, тропологическое и анагогическое толкование, а также набор цитат из Библии и сочинений Отцов Церкви. Этих сборников очень много, больше тридцати в нашей базе, и для каждого из них существует от одной до сотен рукописей. Задача проекта — создать базу знаний, с текстами, доступными онлайн, по которым можно осуществлять какой-то поиск. Моя задача, соответственно, эти тексты оцифровывать. Это можно делать вручную, но на это уйдет вся жизнь. Поэтому мы выбрали наиболее рациональный путь автоматической транскрипции, хотя это не волшебная таблетка. Например, у меня на вычитку рукописи после модели уходит три-четыре месяца, потому что рукописи очень большие: в среднем в них 800–900 страниц, на каждой странице — два столбца и около сотни строк. Однако это быстрее, чем если бы я транскрибировала вручную.
Проект закончится в декабре 2024 года, и совершенно очевидно, что все тридцать рукописей я не смогу откорректировать. Поэтому мы планируем опубликовать на сайте «грязную» транскрипцию, по которой можно проводить много исследований — например, можно распознать именованные сущности (имена и топонимы), провести стилометрический анализ или сделать тематическое моделирование. Например, у меня есть крупнейший из сборников distinctiones, «Бычий словарь» — Dictionarium bovis — Фомы Павийского; он дошел до нас в одном экземпляре. Это текст колоссального объема: он разбит на пять рукописей, в каждой по триста — триста пятьдесят листов, при этом заголовки дистинкций не соответствуют содержанию. Поэтому для того, чтобы в нем ориентироваться, тематическое моделирование будет сделать особенно полезно.
— Помощь каких специалистов требуется в рамках вашего нынешнего исследования? Кого вы привлекаете или, может быть, еще не привлекали, но сейчас понимаете, что вам нужны какие-то конкретные специалисты для решения конкретных проблем и задач?
— Во-первых, я не умею пользоваться Docker’ом (это такое программное обеспечение, которое используют, чтобы устанавливать и запускать приложения в «контейнерах»), поэтому мне нужна помощь с установкой той программы, которую я использую для транскрипции рукописей. Она называется eScriptorium и представляет собой графический интерфейс библиотеки kraken.
Во-вторых, сейчас сайт нашего проекта выглядит очень олдскульно, и мы хотим, чтобы он был посексуальней, но для этого нужен верстальщик, который понимает, как устроены базы данных, и сможет переписать XQuery, которые сейчас используются для поиска. Иногда мне нужна помощь того, кто разбирается в Python с которым я на «вы», так как для того, чтобы массово обрабатывать изображения, которые загружены в eScriptorium, удобно использовать API.
Наконец, в-третьих, мы хотели бы некоторые из текстов опубликовать, обогатив их с помощью TEI, это такая разметка, похожая на HTML, для исторических документов. Когда делают колляцию, то есть когда сводят воедино несколько вариантов одного и того же текста, присутствующих в нескольких рукописях, то, как правило, для издания на бумаге выбирают самый авторитетный источник и после этого в сноске указывают возможные разночтения. Разночтения могут быть разными: отсутствующие знаки, добавленные знаки и замененные знаки. TEI же позволяет параллельно транскрибировать несколько рукописей, не выбирая наиболее авторитетное чтение: можно просто указывать разночтения как иерархически равные, а потом, когда колляция будет завершена, а стемма, то есть «генеалогическое древо» рукописей, построена, можно назначить один из вариантов как наиболее авторитетный, а затем с помощью TEI все это визуализировать. Например, можно показывать только самый авторитетный вариант или варианты чтения из Италии XIV века — это дает гибкость в визуализации текста и в его обработке. Это то, чем я не занимаюсь, но было бы, конечно, славно иметь в команде специалиста в этой сфере.
— Какими навыками надо изначально обладать тем, кто хочет в рамках медиевистики привлечь к исследованиям цифровые инструменты?
— Я считаю, что самый главный навык — это навык палеографа. А еще важно придерживаться одной и той же манеры транскрибировать один и тот же знак. То есть важнейшие навыки — это дисциплина и палеографические способности. И Transkribus, и eScriptorium очень user friendly, чтобы ими пользоваться, не нужно иметь никакого опыта в программировании. Хотя если мы говорим про количественный анализ текста, то, конечно, какое-то базовое понимание программирования понадобится, но это не очень страшно. Я справилась. Думаю, что все остальные тоже могут справиться: я этим занялась, когда мне был тридцать один год. В качестве первого шага могу порекомендовать два замечательных пособия: «Анализ данных и статистика в R» Ивана Позднякова и «Компьютерный анализ текста в R» Ольги Алиевой.
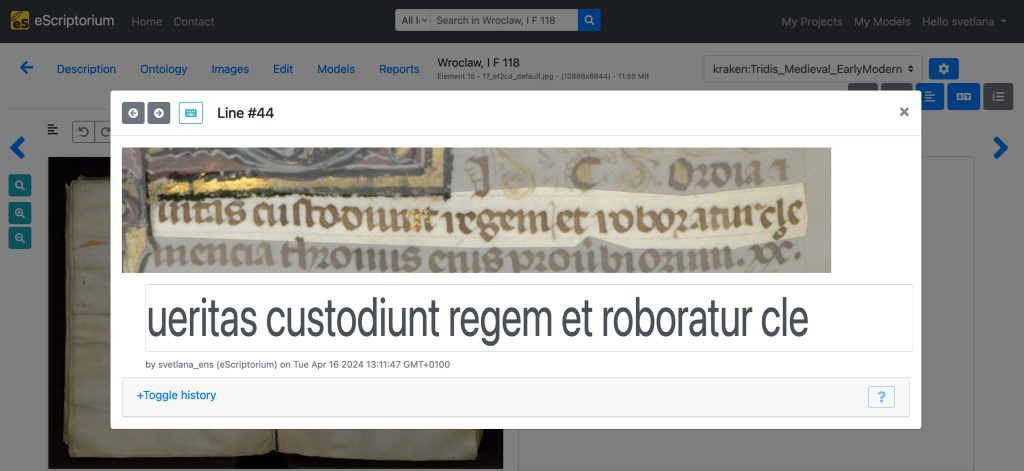 Интерфейс eScriptorium
Интерфейс eScriptorium
— То есть это реально освоить и для этого не нужны какие-то знания вундеркинда?
— Да, инструменты для автоматической транскрипции освоить совершенно реально. Но получить большой объем невычитанной транскрипции — это только подготовительный шаг. Потому что собственно исследование начинается в тот момент, когда вы зададите тексту свои вопросы. Вы можете остановиться на этом этапе и читать «грязную» транскрипцию, обращаясь к рукописи в тот момент, когда заметите, что в том, что программа вам предлагает, нет смысла. То есть вы можете остановиться на сборе данных и обрабатывать их традиционными методами. Другой вариант — применять к этим данным какие-то цифровые методы анализа, и здесь уже нельзя допускать, чтобы программа была черной коробкой, в которую вы загружаете данные, а потом что-то получаете. Если вы не знаете, что она с вашими данными делает, то доверять результату не стоит.
— Какой вы видите финальную точку вашего исследования? Возможно ли ее в целом определить — или сейчас вы стремитесь к промежуточному результату, а дальше будете ставить перед собой более глобальную задачу?
— Проект, посвященный distinctiones, имеет задачу, поставленную не мной, и срок действия, который строго определен тоже не мной. И эту работу я остановлю, как только мне перестанут платить, в том месте, где я окажусь, с тем объемом транскрибированных рукописей, который я соберу. В качестве результата этого проекта может появиться генеральная модель, натренированная на специфическом жанре текстов со специфической лексикой и специфической структурой. Может появиться уже упомянутое исследование при помощи тематического моделирования, которое я начала делать, но для его завершения у меня пока не очень много данных. Возможно, я проведу какой-нибудь стилометрический анализ, потому что есть один сборник, который приписывают трем разным авторам, и можно проверить гипотезу, кто же из них настоящий автор, хотя для стилометрии очень важно, чтобы было с чем сравнивать.
— Сейчас ведется очень много разговоров вокруг искусственного интеллекта и опасений, с ним связанных. Как вы думаете, могут ли быть негативные последствия у ваших исследований? Можно ли вообще таковые выделить?
— Ну разумеется, самый первый популярный страх — что люди разучатся читать рукописи. Студенты будут нажимать на кнопочку, а не сами читать, и мы потеряем какое-то знание, которое у нас было раньше. Я думаю, что будут люди, которые предпочтут делать только автоматическую транскрипцию вместо ручной, но эти люди не останутся в науке, поэтому мне не кажется, что это большая опасность.
Есть опасность появления некачественных критических изданий. Это опасно потому, что, если уже есть одно издание, вероятность того, что появится второе издание того же текста, но более качественное, довольно низка: ведь издатели будут думать, что второе издание не продастся. Но это не ответственность тех, кто занимается автоматической транскрипцией, — это ответственность издателей.
Если говорить про искусственный интеллект и большие языковые модели, я пробовала натренировать «ассистента» на базе модели gpt-3.5-turbo-1106, чтобы он исправлял ошибки в тексте, полученном в результате автоматической транскрипции. В результате эксперимента выяснилось, что, судя по всему, эта модель знакома в основном с классической латынью и поэтому лепит конъюнктив туда, где в моих текстах его не было в помине. В этом можно увидеть опасность того, что появятся публикации не настоящих текстов, а гипероткорректированных чатом GPT. Но, опять же, в этом будет виноват не искусственный интеллект, а те, кто сочтет возможным это опубликовать.
Наконец, мои исследования не безобидны с точки зрения экологии. То количество CPU-минут, которое я использую для тренировки моделей, могло бы отапливать мою квартиру года два. И это нужно держать в памяти: любая тренировка модели, которую ты запускаешь, должна иметь смысл. Больше мне в голову ничего не приходит, но это не значит, что других опасностей нет.
— Известно ли вам что-нибудь о проектах за рамками медиевистики, в которых применяются методы, похожие на те, что используете вы?
— Их масса. Есть конференция пользователей Transkribus, которая проходит раз в год и называется TUC. В рамках этой конференции вы найдете огромный спектр проектов. Я бы выделила три большие группы: исследователи, архивисты и те, кто занимается гражданской наукой, citizen science (последние часто политически и социально ангажированы). Исследователи, как и я, считают автоматическую транскрипцию лишь первым этапом, то есть сбором данных. Архивисты транскрибируют свои данные для того, чтобы сделать их более доступными для сквозного поиска. А проекты citizen science привлекают волонтеров, не обладающих профессиональной экспертностью, для транскрипции чего-либо, на базе чего они будут тренировать модели распознавания текстов. В Канаде, например, этим занимаются люди, которые интересуются автохтонными народами и пытаются сохранять их наследие.
— Как на этой конференции представлены исследователи из России и как в целом в сфере компьютерной гуманитаристики представлены исследователи, аффилированные с российскими институциями?
— Я, к сожалению, плохо знаю российскую сферу. Я знаю, что в Германии есть несколько групп тех, кто пользуется Transkribus для славянской письменности. Есть проект Digital Петр, посвященный рукописному наследию Петра Великого. Есть поиск Яндекса по архивам.
— Как вы думаете, результаты ваших исследований будут интересны только узкому кругу академических специалистов или они могут заинтересовать и более широкую аудиторию?
— То, что я делаю, заинтересует в первую очередь тех, кто будет работать с латинскими средневековыми текстами. Сейчас нередко можно встретить благостные рассуждения про то, что открытие доступа к электронным архивам обеспечивает демократизацию знания, но на самом деле это bullshit, потому что просто доступа в интернет недостаточно для того, чтобы прочитать средневековый латинский текст.
Я предполагаю, что сочетание нескольких инструментов — модели для транскрипции, модели для обработки полученного текста и автоматического переводчика — поможет людям читать средневековые тексты, но я опасаюсь, что на одного инициативного, любопытного любителя найдется не меньше людей, которые пожелают этим злоупотребить, то есть тех, кто захочет, например, отчитаться по гранту автоматическим переводом автоматически же транскрибированной рукописи. Сейчас в медиевистике и византинистике есть люди, которые публикуют на русском языке монографии, представляющие собой автоматический перевод с английского или немецкого, и, к сожалению, издательства это пропускают. Но, опять же, я считаю, что это ответственность научных редакторов и издателей.
Я думаю, будет хорошо, если на сайтах архивов к опубликованным изображениям рукописей будет прилагаться транскрипция, и появится возможность, например, поискать упоминание вашего покойного дедушки в каких-нибудь документах. Но для того, чтобы это принесло свои плоды, необходимо пройти много других этапов, в частности нужно отсканировать рукописи. Например, основу каталога оцифрованных рукописей в национальной библиотеке Франции — а это огромная библиотека с неплохим финансированием — составляют не цветные фото рукописей, а сканы черно-белых микрофильмов с большим количеством шумов и относительно низким разрешением картинки, потому что они делались в 1950-е. Так что, помимо популяризации автоматической транскрипции, есть еще много других звезд, которые должны сойтись, чтобы данные стали по-настоящему доступными для широкой публики.